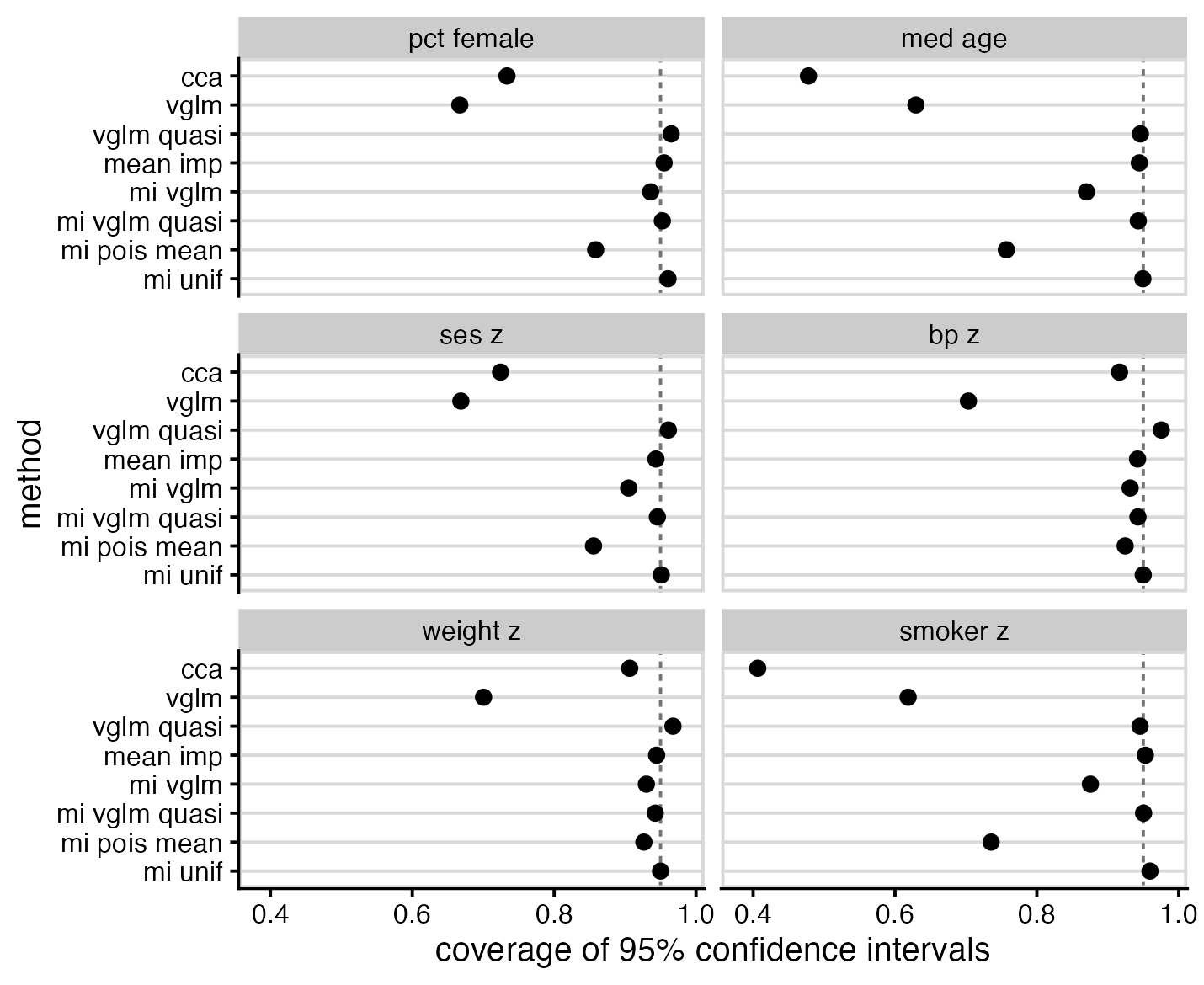
Data with left-censored counts, e.g. “< 5” instead of a small value, need to be handled with care in statistical analysis. Common missing data approaches, including complete case analysis and default options for multiple imputation, perform very poorly. This post evaluates some alternatives, including a multiple imputation-based option that I haven’t seen described previously, which appears to work well.