You are what you ATE: Choosing an effect size measure for binary outcomes
r
statistics
Author
Cameron Patrick
Published
14 July, 2023
Abstract
Wherein I try to make sense of ongoing debates in the statistical community about how to analyse and report clinical trials targeting binary outcomes, and then write some R code to practice what I hesitantly preach.
Introduction
When summarising the effect of a treatment or intervention on an outcome measured on a continuous scale, it’s almost ubiquitous to represent the Average Treatment Effect (ATE) in the form of a difference of means between the treatment and control groups. When the outcome is binary (yes or no, event occurred or event did not occur), there are three commonly-used measures. The risk difference, also known as absolute risk reduction or difference of proportions, is an absolute measure of effect size: the proportion in one group minus the proportion in the other group. The relative risk, also known as the risk ratio, is a relative measure of effect size: the proportion in one group divided by the proportion in the other group. Finally, there is the odds ratio, another relative measure of effect: the odds in one group divided by the odds in the other group. The odds ratio is the odd one out in a few ways, and a bit more controversial.
In the first half of this post, I’ll dive into the controversy. In the middle, I’ll summarise the arguments using a meme. In the second half, I’ll work through an example of estimating odds ratios, risk differences, and relative risks in a simulated example, showing R code examples and hand-calculations. I’m taking a particular interest in the application to randomised controlled trials (RCTs) but most of the issues discussed here apply more broadly.
What’s an odds, anyway?
An odds is the probability of an event occurring divided by the probability of it not occurring. For example, a 50% chance corresponds to an odds of 0.5/0.5 = 1; a 75% chance corresponds to an odds of 0.75/0.25 = 3; a 25% chance corresponds to an odds of 0.25/0.75 = 1/3. Odds are common in gambling and often expressed as ratios, e.g. 1:1, 3:1 or 1:3. Odds ratios are ratios of oddses1. For example, a change from a 50% proportion to a 75% proportion would be a change from an odds of 1 to an odds of 3, representing an odds ratio of 3/1 = 3.
The great odds ratio debate
A lot of noise has been made about why an odds ratio may not be a desirable summary for a treatment effect on a binary variable2. One of the biggest practical problems is that normal humans are unable to correctly interpret an odds ratio (Altman et al., 1998). But for statisticians, there are also deeper concerns to worry about.
In recent years, people3 have become more aware of the mathematical fact of noncollapsibility (Daniel et al., 2021; Greenland et al., 1999; Morris et al., 2022): the marginal4 odds ratio (population-level odds ratio) is not any kind of average of conditional odds ratios (individual-level odds ratios). Marginal odds ratios are the ones you might calculate directly from summary tables. Where do conditional odds ratios come from? They are artefacts of statistical models — logistic regression models, specifically. In the context of a randomised trial, these models predict the probability of an event occurring for each participant based on their treatment assignment and other variables measured prior to treatment (usually demographic characteristics, but could be any variable that is informative of the outcome)5. The second half of this post shows a worked example where every participant has the same conditional odds ratio of treatment, but the conditional odds ratio is not equal to the marginal odds ratio.
The problem of noncollapsibility is relevant to the analysis and reporting of randomised controlled trials. The ICH E9(R1) estimand framework for clinical trials requires a “population-level summary” be defined for each outcome without reference to method used to estimate it. In the language of causal inference, that’s describing an Average Treatment Effect (ATE), and the odds ratio isn’t one6.
Risk differences (the difference in probability attributable to a particular treatment) and relative risks (the ratio of probabilities due to a particular treatment) avoid both the interpretability and noncollapsibility problems of odds ratios. However, statisticians are usually taught to analyse binary outcomes using logistic regression, the direct output7 of which is odds ratios, so odds ratios are ubiquitous in the research literature. Someone on Stats Twitter rediscovers all of this every few months and starts a heated argument where nobody goes away happy.
Surprisingly, many statisticians prefer collapsibility.
Personally, I’m a fan of risk differences for communicating potential risks to an individual, ideally presented alongside the baseline level of risk. There’s some evidence that patients and clinicians find these measures easier to interpret than relative measures (Zipkin et al., 2014), especially when presented in the form of a natural frequency, like “6 in 1000 people” rather than “0.6%”.
So, with all those disadvantages, will anyone speak up in support of odds ratios? Should we all hang up our logistic regression hats for good?
In defense of logistic regression
Statistical analyses are often adjusted for covariates, either to reduce confounding (in observational studies) or improve power (in randomised trials). Adjusting for covariates requires specifying some kind of model. If we’re using a generalised linear model8, the mathematical form of covariate adjustment will depend on whether you are modelling log-odds (logistic regression model, where model parameters correspond to an odds ratio), probability (linear probability model, where model parameters correspond to a risk difference) or log-probability (quasi-Poisson or log-link binomial model, where model parameters correspond to a relative risk). When modelling risk differences or relative risks directly, it’s possible to end up with impossible predicted probabilities: “probabilities” which are less than zero or greater than one. Using logistic regression avoids this problem, because any real number on the log-odds scale translates to a probability between zero and one. Any odds ratio can be applied to any level of baseline risk without making mathematicians sad9.
There are also compelling — but not universally accepted — arguments that despite the difficulty in interpreting odds ratios, conditional odds ratios are more likely to be transportable between different levels of baseline risk than risk differences or relative risks (Doi et al., 2022; Senn, 2011). This is an empirical matter, not a mathematical one, and the evidence is not clear-cut. If we accept this, though, it is another reason to prefer logistic regression for statistical modelling. Effect size measures being “transportable” is another way of saying that the effects are closer to being additive on the scale that effect measure lives on (probability, log-probability, or log-odds). In the context of regression models, using a scale where the effect size is more transportable reduces the need for interaction terms, which can only be estimated well in large samples.
It’s possible to model the data using logistic regression, and then use that model to produce other quantities of interest, such as average risk differences. This approach is described in Permutt (2020), which has some of the best writing I’ve encountered in a statistics paper — being written in the form of a dialogue between a randomiser (the “causal inference” perspective) and a parameteriser (the “statistical modelling” perspective) walking through the Garden of Eden, planning to conduct and analyse a clinical trial. Does this method give us the best of both worlds: the modelling advantages of logistic regression and the interpretability advantages of risk differences and relative risks?
Permutt (2020) also considered what information different audiences might want from the results of a clinical trial: regulator, patient, and scientist. There’s a fourth audience which I think is worth considering, only very briefly mentioned by Permutt: the meta-analyst, trying to aggregate information from multiple trials.
Permutt argues in favour of the ATE being the main quantity of regulatory interest:
The average treatment effect should be of regulatory interest, however. The primary analysis of outcome should be of a variable that is reasonably linear in utility to the patient. Then, if and only if the average effect is positive, the ensemble of patients can be said to be better off under the test condition than under the control. This is perhaps the weakest imaginable statistical condition for approval of a drug product, but it is surely a necessary condition.
Permutt notes that studies designed to be able to detect average treatment effects are unlikely to be adequate for patient-specific decision making or providing a more detailed scientific understanding.
Marginal adjusted estimates may be robust, but may not accurately estimate RD for either any patient in the RCT or for the clinical population to which RCT results are to be applied, because in effect they assume that the RCT sample is a random sample from the clinical population, something not required and never realized for RCTs.
This refers to the distinction between the population average treatment effect (PATE) and the sample average treatment effect (SATE). RCT participants are not random samples from any population, not even from the eligible pool of participants for a particular study. But the regulator’s decision that Permutt described earlier is motivated by generalising to a broader population, implicitly relying on properties of the PATE. It’s not clear to me whether there are likely to be any real-world scenarios where both (1) the practical conclusions drawn from the SATE and PATE would be different; and (2) the conditional odds ratio derived from the RCT sample is in agreement with the PATE but the risk difference SATE is not.
I am a coward and not (yet?) willing to take a strong position in this fight, but am always sympathetic to the idea that a single number is rarely sufficient to describe scientific evidence (see also: p-values). At some point I might write another blog about Harrell’s idea of plotting the distribution of estimated patient-level treatment effects, which is intriguing, although I struggle to see the practical purpose of it. Harrell’s other writing on this topic is also worth reading:
Unadjusted Odds Ratios are Conditional demonstrates noncollapsibility and argues that conditional odds ratios are more useful than marginal odds ratios.
One issue which I remain unclear about is whether randomised trials powered to detect main treatment effects are likely to provide reasonable estimates of patient-specific baseline risk — a simpler task than patient-specific treatment effects, but still outside of the usual design remit for an efficacy trial. Common analytical approaches for clinical trials have good properties for estimating average treatment effects when the covariates are regarded as nuisance parameters (White et al., 2021), but are not guaranteed to perform so well if the effects of the covariates are themselves of interest.
Finally, there is the meta-analytic perspective to consider. An effect size which is less heterogeneous between studies is once again desirable. If arguments about the transportability of odds ratios by the Harrell, Senn, Doi, and others are to be believed, we should report conditional odds ratios, as those are likely to be the most useful for meta-analysts. The CONSORT guidelines for reporting randomised trials (Moher et al., 2010) state that both absolute and relative effect sizes should be reported for binary outcomes. I think there is merit in reporting all commonly-used effect size measures: risk difference, relative risk, and odds ratio. This provides the most flexibility for future meta-analysts.
Summary, in meme format
If all of that was a bit much to take in, maybe this will help:
True facts on both sides.
In the rest of this post I’ll demonstrate how odds ratios are noncollapsible and show how to calculate risk differences and relative risks from logistic regression models using R and the marginaleffects package.
An example
This is the story of some hypothetical researchers who did a randomised controlled trial (RCT) where 560 patients were randomly assigned to either a treatment or control condition. The primary outcome of the trial was a binary measure, indicating whether a patient’s condition had worsened after 6 weeks. The scenario is based on one from Frank Harrell’s blog, with the details changed and embellished.
The hidden R code block below loads some R packages and sets up some simulated data for this trial.
Looking at a 2-way table of our hypothetical trial, we can see that the worse outcome (“1”) is more common in the control group (37%) than the treatment group (30%). This is an absolute risk reduction of 7%, a promising sign that our treatment may be beneficial.
Just looking at a table won’t convince anybody, though. At this point, our hypothetical researchers asked a statistician to help out10. The hypothetical statistician immediately realised the need to estimate the treatment effect in some way that also quantified its uncertainty. A binary logistic regression model seemed like a suitable way to examine the effect of the treatment on the outcome.
The table below shows the results of this logistic regression: an odds ratio of 0.73 (95% CI: 0.51 to 1.03). The odds ratio being less than 1 indicates that the treatment was beneficial (since the outcome occurring was bad, in this case) but the p-value of 0.074 indicates this effect is not statistically significant. The researchers were sad, their dreams of publishing in the British Medical Journal scuppered.
tbl_regression(lrm_unadj, exponentiate =TRUE)
Characteristic
OR1
95% CI1
p-value
treatment
Control
—
—
Treatment
0.73
0.51, 1.03
0.074
1 OR = Odds Ratio, CI = Confidence Interval
Adding a covariate
Just as the statistician was finishing writing up the results, the researchers mentioned that the patients they recruited came from two different groups, one of which was known to have much worse outcomes than the other.
“Does that matter?” they asked.
“Well, using this information could improve your statistical power” said the statistician.
The statistician made another 2-way table, stratified by the risk group. Through some fluke, exactly half of the trial sample was low risk and the other half high risk, perfectly balanced across treatment arms. It turned out that while only 14% of the low risk patients in the control arm experienced the worse outcome, 60% of the high risk patients in the control arm experienced that outcome.
Looking at the coefficients in this model, we can see that the estimated effect of treatment has increased: the odds ratio is further away from 1, now being 0.67 (95% CI: 0.45 to 0.99) instead of 0.73 (95% CI: 0.51 to 1.03). The p-value has decreased from 0.074 to 0.045, meaning that the treatment effect is now statistically significant.
tbl_regression(lrm_adj, exponentiate =TRUE)
Characteristic
OR1
95% CI1
p-value
treatment
Control
—
—
Treatment
0.67
0.45, 0.99
0.045
risk
Low risk
—
—
High risk
9.00
5.91, 14.0
<0.001
1 OR = Odds Ratio, CI = Confidence Interval
The researchers went home happy, dreaming once again of publishing in a high impact factor journal, but the statistician was left with a nagging feeling that something was not quite right. The covariate was balanced between treatment groups, with equal numbers of low risk and high risk assigned to each treatment. Undergraduate linear models courses taught that adding a covariate to the model which is balanced between treatment groups shouldn’t change the coefficient for treatment, only the standard error. Why, then, did the estimates change like that? Is logistic regression different from linear regression in this regard?
Hand calculations: back to the 2-way table
Let’s take another look at the 2-way table and do some hand calculations.
treatment
Total
Control
Treatment
outcome
0
176 (63%)
196 (70%)
372 (66%)
1
104 (37%)
84 (30%)
188 (34%)
Total
280 (100%)
280 (100%)
560 (100%)
The marginal risk difference is the difference between treatment and control groups in the proportion of patients experiencing the outcome event. From the table above, ignoring the covariate, we can calculate a risk reduction of 0.071:
104/280-84/280
[1] 0.07142857
The marginal odds ratio is the ratio of the oddses for treatment and the control group, where the odds is itself the number who experience the outcome event divided by the number who do not11. We can calculate the marginal odds ratio here as 0.73, the same as the unadjusted logistic regression:
(84/196) / (104/176)
[1] 0.7252747
Now let’s look at the table stratified by risk, and see how that affects our calculations.
Low risk
High risk
Control
Treatment
Total
Control
Treatment
Total
outcome
0
120 (86%)
126 (90%)
246 (88%)
56 (40%)
70 (50%)
126 (45%)
1
20 (14%)
14 (10%)
34 (12%)
84 (60%)
70 (50%)
154 (55%)
Total
140 (100%)
140 (100%)
280 (100%)
140 (100%)
140 (100%)
280 (100%)
Using the same formula as before, we can calculate a risk difference of 0.043 in the low risk group, 0.100 in the high risk group, and the equally-weighted average of those two (because the two risk groups are equally common in this example) is 0.071, same as the marginal risk difference calculated above.
# conditional risk difference in the low risk group20/140-14/140
[1] 0.04285714
# conditional risk difference in the high risk group84/140-70/140
[1] 0.1
# average of conditional risk differences is the marginal risk difference0.5*((20/140-14/140) + (84/140-70/140))
[1] 0.07142857
Using the formula for odds ratios, we can calculate an odds ratio of 0.67 in the low risk group and 0.67 in the high risk group. The conditional odds ratios in both groups are equal, and equal to the conditional odds ratio from the adjusted logistic regression, but are different from the marginal odds ratio. This is noncollapsibility in action.
# conditional odds ratio in the low risk group(14/126) / (20/120)
[1] 0.6666667
# conditional odds ratio in the high risk group(70/70) / (84/56)
[1] 0.6666667
In this example, we observed a treatment-by-risk-group interaction on the risk difference scale (absolute risk reduction of 0.041 in the low-risk group, absolute risk reduction of 0.100 in the high-risk group) but not on the odds ratio scale (conditional odds ratio of 0.67 in both groups). There is no mathematical requirement for the odds ratio scale to have a smaller interaction than other scales, but it is mathematically impossible for there to be no interaction on any scale unless the effect size is zero. This issue is discussed in detail from the perspective of psychological research in Rohrer & Arslan (2021).
Calculating risk difference and relative risks using the marginaleffects package
The researchers returned to the statistician, requesting adjusted and unadjusted risk differences and relative risks to report in their paper. Fortunately, the statistician was familiar with the marginaleffects package, which makes it fairly easy to calculate risk differences from logistic regression models12.
Risk differences
The avg_comparisons() function calculates differences in one variable, averaged across the observed distribution of the other variables. By default it does this calculation on the response scale, i.e. predicted probability, which is what we want for a risk difference. For the unadjusted model, we get an average risk reduction of 7.1% (95% CI: -0.1% to 14.9%).
Term Contrast Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
treatment T - C -0.0714 0.0398 -1.79 0.0727 3.8 -0.149 0.00657
Columns: term, contrast, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high
For the adjusted model, we get an average risk reduction of 7.1% (95% CI: 0.0% to 14.1%).
avg_comparisons(lrm_adj, variables ="treatment")
Term Contrast Estimate Std. Error z Pr(>|z|) S 2.5 % 97.5 %
treatment T - C -0.0714 0.0354 -2.02 0.0437 4.5 -0.141 -0.00201
Columns: term, contrast, estimate, std.error, statistic, p.value, s.value, conf.low, conf.high
Unlike the odds ratio, the point estimate of the risk difference didn’t change when we added the covariate, but its estimate got more precise: the confidence interval shrank.
Relative risks
To get relative risks using avg_comparisons(), we need to ask for the average of the log of the ratio between treatment conditions (lnratioavg in the code below), and then exponentiate that.
For the unadjusted model, the relative risk is 0.81 (95% CI: 0.64 to 1.02).
Compared to the unadjusted model, the point estimate hasn’t changed but the confidence interval shrank. Like risk differences, and unlike odds ratios, relative risks are collapsible.
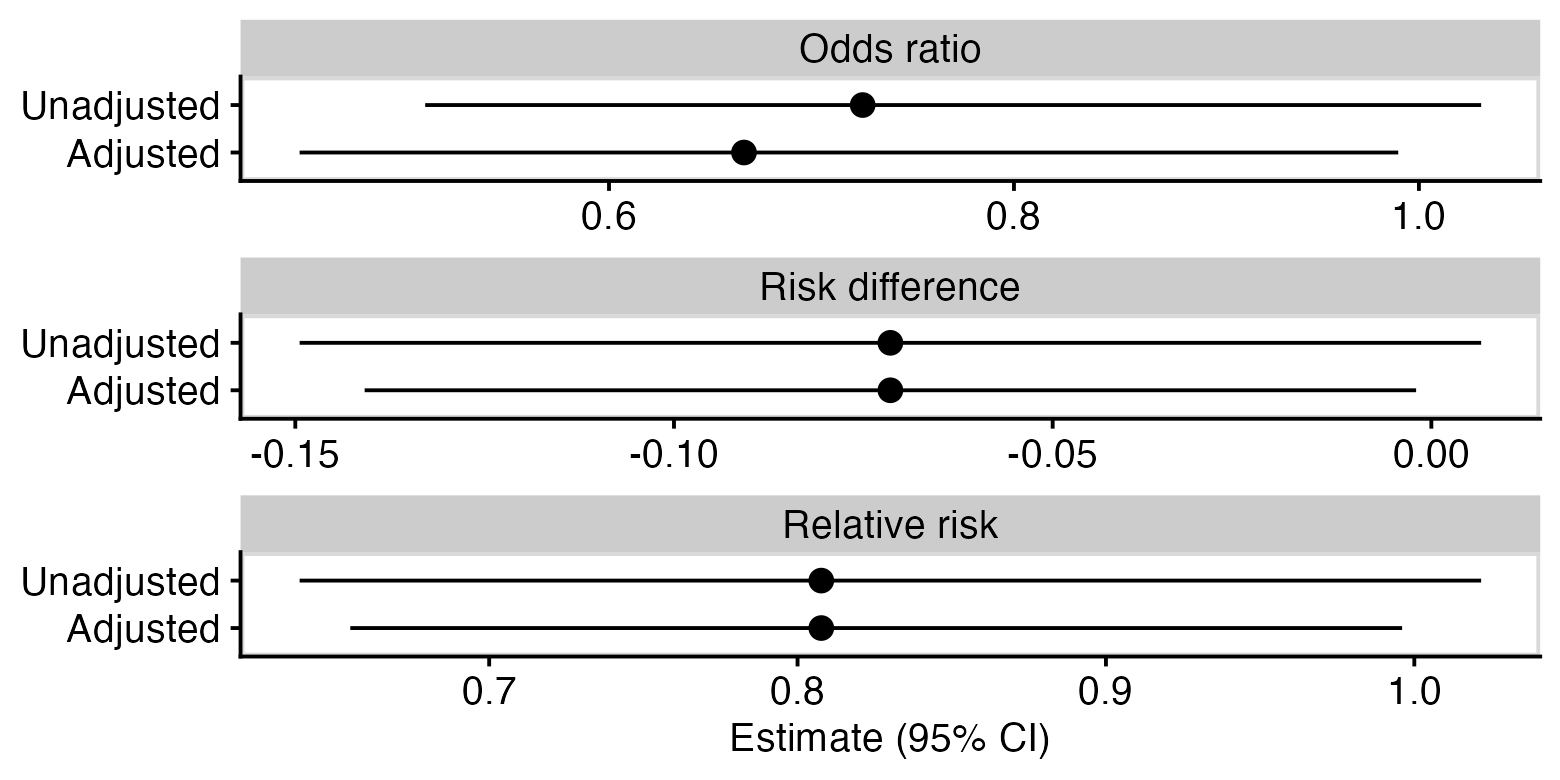
In pictures
One last way of showing the same thing: below is a plot of unadjusted and adjusted odds ratios, risk differences, and relative risks. You can see that for the odds ratio, the adjustment has moved the point estimate but not made the confidence interval narrower, whereas for the other measures, the point estimate has not changed but the confidence intervals are narrower for the adjusted estimate.
Thanks to those who provided feedback on earlier versions of this post, some which resulted in substantial revisions and improvements:
Isabella Ghement
Lachlan Cribb
Solomon Kurz
This does not represent an endorsement of this post by any of the above. Mistakes and opinions are entirely my own.
Feedback welcome, especially any corrections in cases where I may have misunderstood or misattributed arguments, or made clear factual errors.
References
Altman, D. G., Deeks, J. J., & Sackett, D. L. (1998). Odds ratios should be avoided when events are common. BMJ, 317(7168), 1318–1318. https://doi.org/10.1136/bmj.317.7168.1318
Daniel, R., Zhang, J., & Farewell, D. (2021). Making apples from oranges: Comparing noncollapsible effect estimators and their standard errors after adjustment for different covariate sets. Biometrical Journal, 63(3), 528–557. https://doi.org/10.1002/bimj.201900297
Doi, S. A., Furuya-Kanamori, L., Xu, C., Lin, L., Chivese, T., & Thalib, L. (2022). Controversy and Debate: Questionable utility of the relative risk in clinical research: Paper 1: A call for change to practice. Journal of Clinical Epidemiology, 142, 271–279. https://doi.org/10.1016/j.jclinepi.2020.08.019
Greenland, S., Pearl, J., & Robins, J. M. (1999). Confounding and Collapsibility in Causal Inference. Statistical Science, 14(1). https://doi.org/10.1214/ss/1009211805
Moher, D., Hopewell, S., Schulz, K. F., Montori, V., Gotzsche, P. C., Devereaux, P. J., Elbourne, D., Egger, M., & Altman, D. G. (2010). CONSORT 2010 Explanation and Elaboration: updated guidelines for reporting parallel group randomised trials. BMJ, 340(mar23 1), c869–c869. https://doi.org/10.1136/bmj.c869
Morris, T. P., Walker, A. S., Williamson, E. J., & White, I. R. (2022). Planning a method for covariate adjustment in individually randomised trials: a practical guide. Trials, 23(1), 328. https://doi.org/10.1186/s13063-022-06097-z
Rohrer, J. M., & Arslan, R. C. (2021). Precise Answers to Vague Questions: Issues With Interactions. Advances in Methods and Practices in Psychological Science, 4(2), 251524592110073. https://doi.org/10.1177/25152459211007368
Senn, S. (2011). U is for Unease: Reasons for Mistrusting Overlap Measures for Reporting Clinical Trials. Statistics in Biopharmaceutical Research, 3(2), 302–309. https://doi.org/10.1198/sbr.2010.10024
White, I. R., Morris, T. P., & Williamson, E. (2021). Covariate adjustment in randomised trials: canonical link functions protect against model mis-specification. https://doi.org/10.48550/ARXIV.2107.07278
Zipkin, D. A., Umscheid, C. A., Keating, N. L., Allen, E., Aung, K., Beyth, R., Kaatz, S., Mann, D. M., Sussman, J. B., Korenstein, D., Schardt, C., Nagi, A., Sloane, R., & Feldstein, D. A. (2014). Evidence-Based Risk Communication: A Systematic Review. Annals of Internal Medicine, 161(4), 270. https://doi.org/10.7326/M14-0295
Footnotes
This plural form is non-standard but I’m trying to make it happen.↩︎
Statisticians use the word “marginal” to refer to a population-level average, or an integral. Economists, on the other hand, use the word “marginal” to refer to a change in a quantity, or a derivative. These opposite meanings can potentially cause a lot of confusion.↩︎
This issue is also sometimes raised in longitudinal studies, where it is said that generalised linear mixed models (GLMMs) target conditional odds ratios while generalised estimating equations (GEEs) target marginal odds ratios. This has led to an epidemic of epidemiologists applying GEEs to their data. As far as I understand it, this claim is only half true: odds ratios from GEEs target what you’d get from a GLMM after marginalising over random effects, but are still conditional on other covariates in the model (fixed effects in a GLMM). Confused yet? Probably not nearly as confused as you should be.↩︎
Neither is the hazard ratio, which means — despite its ubiquity — Cox regression for survival analysis is technically not allowed by the estimand framework.↩︎
Technically, logistic regression directly estimates a conditional difference of log-odds. The difference on the log scale is usually exponentiated and reported as an odds ratio.↩︎
Or even an additive model — exactly the same point applies to Generalised Additive Models (GAMs).↩︎
At this point you may find yourself inclined to avoid logistic regression purely to spite the mathematicians. I don’t blame you.↩︎
Statisticians love being asked to help at the last minute.↩︎
The odds ratio is a ratio of ratios, no wonder nobody understands them.↩︎
One thing to be aware of is that the standard errors are derived using the delta method, which is a large-sample approximation. There is experimental support for bootstrapping and simulation-based inference in the marginaleffects package to get more accurate estimates in small samples, but this blog post isn’t going there.↩︎